Ensemble Methods - Stacking
2017-09-04 12:05:54 +0800
Every model has different advantages and disadvantages. Based on the principle that no model is perfect, ensemble methods learn and combine the prediction of each model to increase accuracy. It is widely used in Kaggle and most winners used it in their final models. This post is written when I am learning ensemble methods and using it in Zillow Price Competition. It includes several papers’ review and some of my understanding.
Introduction of Stacking
The basic idea of stacking is to predict based on the predictions of a series of different models. A two layers stacking generation is showed below:
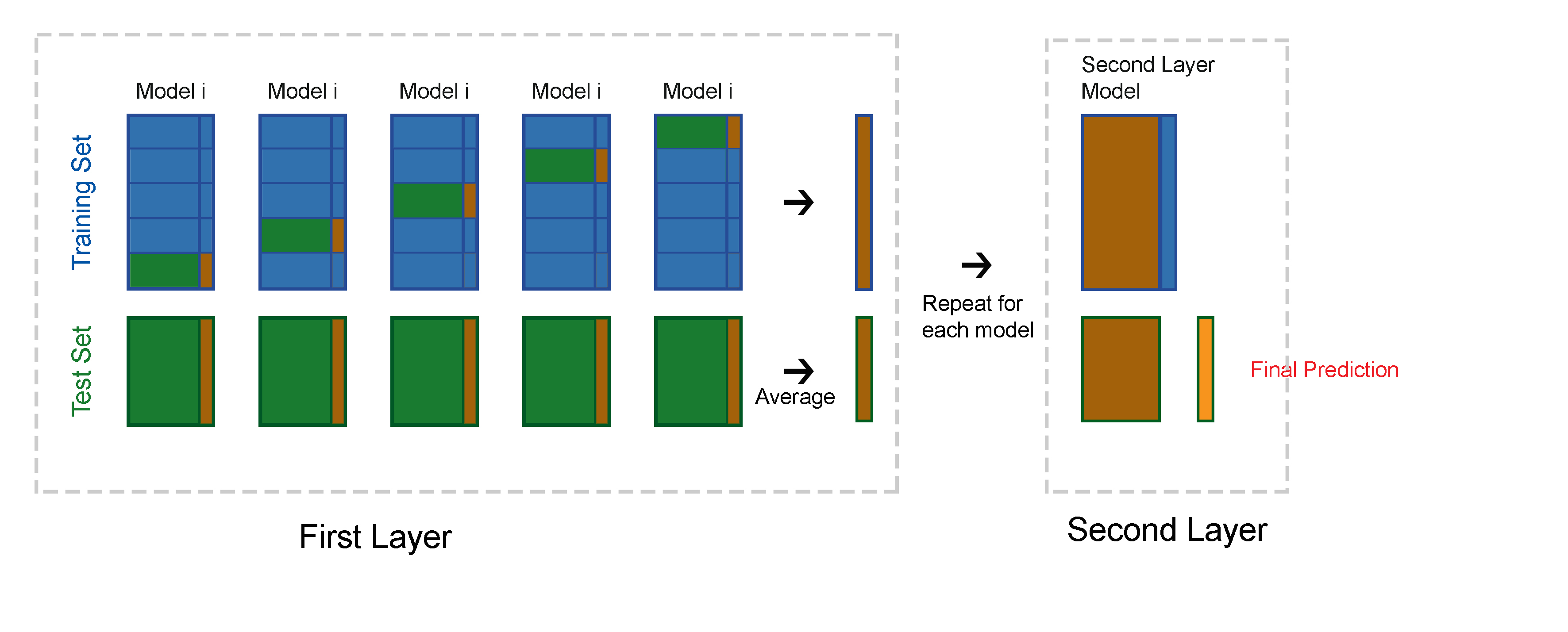
- First Layer
- Split the training set into m parts
- Fit a model on m-1 parts, and predict on the left one part of train set and the whole test set.
- Switch and repeat the last step for m times with the same model, then get one prediction of whole training set and m prediction of the test set.
- Average the m prediction of the test set into one.
- Repeat all above for each first-layer base model (n). (Get n predictions on the training set and n predictions on the test set.)
- Second layer
- Use the predictions from first layer to train the second-layer stacking model, then predict on the test set to get the final prediction.
Summary of Some methods/Techs
Feature-Weighted Linear Stacking is introduced by the second winner team of Netflix competition. It uses linear regression as the 2nd-Layer stacking model and add meta-features into the second layer. The basic idea behind this model is that some model might perform better on part of data. So, adding meta-features can help locate this part.
The standard linear regression learned the constant weight $w_i$ from $b(x) = \sum_i w_i g_i(x)$. While Feature-Weighted linear stacking modles the weights $w_i$ as a linear function of the meta-features, $w_i(x) = \sum_j v_{ij}f_j(x)$ ($f_j(x)$ is a meta-feature). Combining the two parts together is actually still a linear regression:
with the M*L features $f_j(x) g_i(x)$.
StackNet is a stacking framework implemented with a software in JAVA. The developer Μαριος Μιχαηλιδης KazAnova ranked top3 on Kaggle and got many top rank using this framework. It resembles a feedforward neural network and uses Wolpert’s stacked generalization in each levels.
Tips
1. The second layer does not work better than one of the base models.\
To check 1: Base models’ performance.
To check 2: Overfitting.
Other Resource:
- Kaggle Ensemble Guide 07/11/2015